Design Uber
1. 理解需求
1.1 商业目的
让用户用手机方便地在城市里打车,提供明确的价格和等待时间。
1.2 功能性需求
匹配乘客和司机 (Matching)
定价 (Pricing/Surge)
预计等待时间 (ETA)
1.3 非功能性需求
极高可用性 (Very high availability) - 任何系统宕机都会有真实的乘客和司机无法打车。
高效合理地匹配乘客和司机
2. 资源估算
2.1 假设
乘客 100M MAU
平均每人每月5次打车
平均每人每月20次访问匹配 (Matching) 服务
平均每次打车时长15分钟
每4秒与服务器同步位置信息
2.2 估算
每月同步位置信息访问量 = 月活乘客数量 * 打车分钟数 * 每分钟访问量 = (100*10^6)*(15*5)*(60/4)
每秒同步位置信息访问量 (QPS) = 每月同步位置信息访问量 / 30 / 24 / 3600 = 43402
每秒匹配服务访问量 = (100 * 10^6) * 20 / 30 / 24 / 3600 = 771
3. High-level Diagram

4. 数据结构与存储
4.1 Trip Table
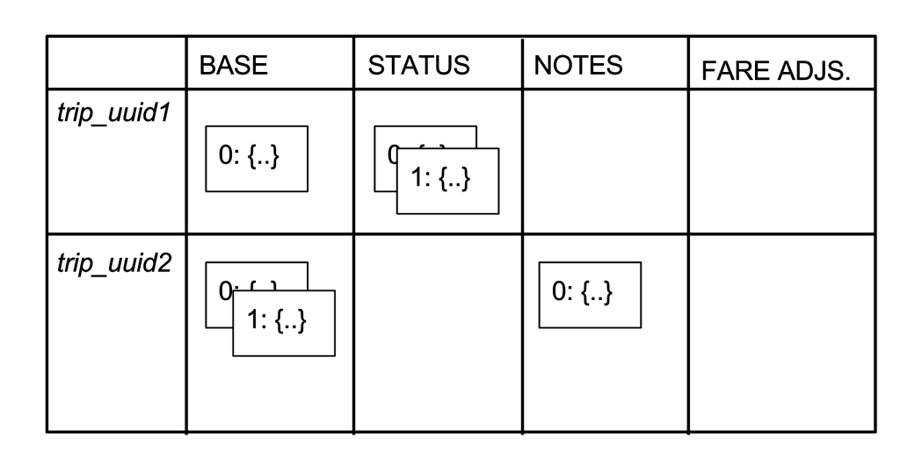
Base: driver_uuid, trip_timestamp
Status: payment status
Notes: note from Operation
Fare Adjustment: fares that are adjusted
四列对应四个不同时间的数据存储来避免 Race condition,第一列写在完成 trip,第二列写在付款,第三列是由运营人员写入,第四列是由运营人员实施调整。
5. 核心子系统设计
我们着重设计供需服务。供需服务提供两个功能,更新乘客和司机的位置以及匹配司机与乘客。
5.1 Websocket vs HTTP
每四秒钟,乘客和司机的手机就会向后台发送位置信息,从前面的估算中也能看到,QPS 相当高,我们可以考虑用 Websocket 来实现双向交流,这样可以省去反复handsake 的时间。
5.2 位置数据的存储
位置数据有效期非常短 (ephemeral),在数秒内就会产生变化。这样的特点驱使我们去使用 in-memory 的方案。
Redis 一类的 Cache,对于每一个司机,我们都存一个位置。这样更新位置很快速,但是匹配时,需要遍历整个 Cache,速度慢。
Geospatial worker。使用一系列的 worker 来负责存储每个区域里的位置信息。更新位置时需要找到对应的 worker,匹配时去找相关的几个 worker,不需要遍历。这些worker 之间如何协作在下一节中提到。
后者更优。
5.3 Worker协作 (Ringpop)
在 Facebook 和 Google 这类服务中, 我们一般使用 Stateless Service + Cache + DB来实现 Horizontal Scaling。
在 Uber 供需服务的情景下,DB 不必要了,我们可以考虑合并 Stateless Service + Cache,形成一个 Stateful Serivce。至于如何扩容以及检索正确的服务器,我们可以把 Consistent Hashing 的借用到 Service 层面上。
用户会任意访问一台供需服务的服务器(就是前面提到的 Geospatial worker)
服务器随后 Forward Request 到其中负责这个地理位置的服务器上做位置更新和匹配的处理。这样位置数据只要存在多台服务上就能保证存储位置数据的可靠性,同时加速访问效率。
因为需要 Forward Request,每一台服务器都会知道别的服务器在Hash Ring上的位置。
如果需要加减机器,Ringpop 内部的 Gossip membership protocol 会重新分配每台机器在 Hash Ring 的位置。
5.4 匹配逻辑
最直接的想法是找直线距离最近的闲置司机。我们可以通过 Ringpop 找到临近片区的的司机,挑出一个最近的匹配。
这种做法有几个问题。
直线距离近不代表两点间行车的时间最短
乘客即将下车的司机可能更合适
乘客可能对车有要求 (Uber Pool vs Uber X)
加入以上的几点考虑,匹配就更完善了。
5.5 容灾设计
Uber 的服务的可用性要求要高于 Facebook 和 Google 这样的纯线上服务。如果我们的供需系统下线了,会造成乘客无法坐车,司机无法接单的窘境。
如果我们失去了整个数据中心的 Geospatial worker,我们如何保证 Uber 的服务还能继续?
我们需要有备份的数据中心。每一个城市都会有一个主要的数据中心来提供服务,如果无法访问,去找另一个备份数据中心。同时这个备份的数据中心会是另一些城市的主要数据中心。这样可以减少资源的空置。
联系到前面提到的 Stateful Service,在整个数据中心消失的情况下,用户的位置信息也消失了。这时候我们会把司机和乘客的手机里的信息重新上传到备份数据中心,来恢复 Stateful Service 的状态。
6. 接口设计
POST /driver/location/
POST /rider/location/
GET /driver/match (rider_uuid, lat, long, product)
7. 扩展性,容错性,延迟要求
总结一下之前提到的一些设计要素。
7.1 扩展性
Ringpop 中 worker 可以随时加减
Load Balancer
Schemaless /Big Table
7.2 容错性
多数据中心
用司机乘客的手机来恢复服务器的状态
Schemaless /Big Table
7.3 延迟要求
Websocket Connection
8. 监控和警报
8.1 常规
服务 QPS
服务延迟
服务可用性 (Availability)
Ringpop worker load
8.2 系统错误
使用 Kafka 将系统中的 Error 和 Exception 汇总,方便分析。
8.3 行程日志 (Trip Log)
Uber 需要做到符合所在地的法律法规,并帮助所在地政府优化交通。这里我们需要把行程的信息从 Kafka 中读出来组成提供给政府的报告,以备不时之需。
9. 专题深挖
9.1 地图分区
在“核心子系统设计”中,我们讨论了把不同地图区块分配到不同的 geospatial worker上。我们如何科学给地图分块?
我们可以参考 Google S2 Library。
Cell Level (0-30) 由大到小的分区。Level 30 cell 大概在 1cm 左右。
使用 Hilbert Curve 尽可能让相近的分区编码接近。
这个设计很有难度。我白板了一下,发现很多知识点是我自己想不到的,例如Ringpop和S2。感谢这篇题解给了一个深入研究的索引。
有个面试相关的问题请教:如果在面试中提议使用stateful serivce这种不太常规的做法,可能会触发一些stateful vs. stateless使用场景的讨论。我想了一下,如果server side需要跟踪记录user states,那必用stateful不可;如果只是根据地理位置来决定哪个Geospatial worker,理由似乎不够强,因为这个是可以用stateless service + distributed data store解决的,但是出于性能原因,data partitioning需要按照地理位置来。(根本上说,Uber不用Redis,但是自己实现了一些Redis的细节,导致了stateful的结果。)为了性能优化而不用stateless,在时间有限的面试中能不能说服面试管?
顺便请教一下api的写法:譬如说GET /driver/match (rider_uuid, lat, long, product) 我知道这不是stateless service,所以不用遵循REST api的规范。不过这样写看起来真的很像REST,尤其那个resource url。不知道写成标准api函数的方式会不会容易避免误会? match(rider_uuid, lat, long, product)
•
•
分享 ›

5.2 位置数据的存储: Lyft用的是Redis的方案,具体是如何设计的不是很清楚。估计是,用consistent hashing,把位置信息的key和redis servers(nodes)都放入一个大环中。这个方法,其实和uber也差不多,但用了现成的redis。
Lyft 的做法可以看一下这个 Tech Talk - Uber Lyft 对于位置数据的做法的主要区别在于 Uber 用 Stateful Service 而 Lyft 把 State 存在 Redis.
每月同步位置信息访问量,是不是还需要加上driver的位置同步次数?
Last updated