Distributed Lock
分布式锁是强一致性系统的基础。在分布式系统里,我们往往需要在一致性和可用性之间做抉择 (CAP Theorem)。大多数时候,在诸如设计 Twitter, Facebook 等服务的情况下,我们都会选择可用性而舍弃一致性,退而求其次采用最终一致性 (Eventual Consistency)。然而在另一些情况下,诸如一些涉及交易 (Transaction) 的服务中,我们就要很强的一致性要求,使得我们需要舍弃高可用性。
这道题的特别之处就是要我们打破设计高可用性系统时的思维定式,思考强一致性的实现方法。同时因为本题所设计的并不是一个具体的服务,而是一个中间件 (Middleware),答题流程会相应变化。
1. 理解需求
1.1 提问
本题的功能性需求根据面试官的指引,可能走向几个不同的方向,所以我们必须在面试之初问出一个关键的问题:锁在正确 (Correctness) 与效率 (Efficiency) 之间如何取舍?
怎么选择取决于我们的锁的作用是什么。
正确优先 - 锁是用来防止不同的节点同时修改同一个资源。一旦该资源被同时修改,依赖于该资源的系统会出现诸如数据丢失,系统永久性不一致等严重问题。
效率优先 - 锁不需要像上一点中所说的绝对的正确性。锁是用来防止不同节点反复进行重复的计算。一旦锁的正确性出现问题,系统会浪费一定量的运算,出现有限的问题 (比如用户收到两封同样的邮件),但不会造成严重后果。
这个问题是由 Martin Kleppmann,畅销系统设计著作 Designing Data-intensive Applications 的作者在他关于分布式锁的博客中提出的,有兴趣的同学可以将其当做延伸阅读。
1.2 面试官的指引
当你提出这个问题的时候,面试官可能会给三种指引:
效率优先
正确优先
都设计
值得注意的是,1 和 2 在这里是递进的关系,因为在这里绝对的正确性 + 一般的效率远比多数时候的正确性 + 高效率要难达到。在下面的章节中,我们会先介绍效率优先的设计方案,然后对其进行一系列改进,使其满足正确性的要求。
1.3 功能性需求(效率优先)
在任何一台机器都可能随时宕机的情况下,尽可能保证系统仍能运行
不能有死锁
实现多数时候正确的分布式锁(避免多台客户端上的进程进行相同运算,浪费运算资源)
保证系统的高效率
1.4 功能性需求(正确优先)
在任何一台机器都可能随时宕机的情况下,尽可能保证系统仍能运行
不能有死锁
实现正确的分布式锁(多台客户端上的进程不能同时修改锁所保护的资源,造成严重错误)
允许为了正确性,一定程度上牺牲系统运行效率
2. High-level Diagram
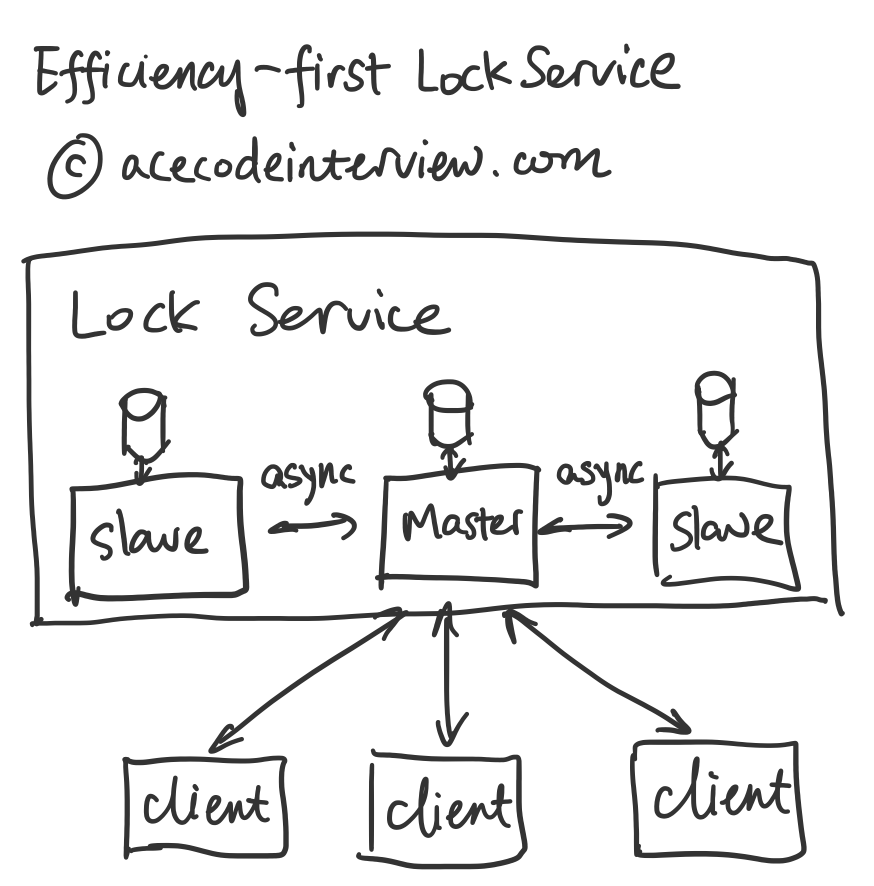
2.1 效率优先
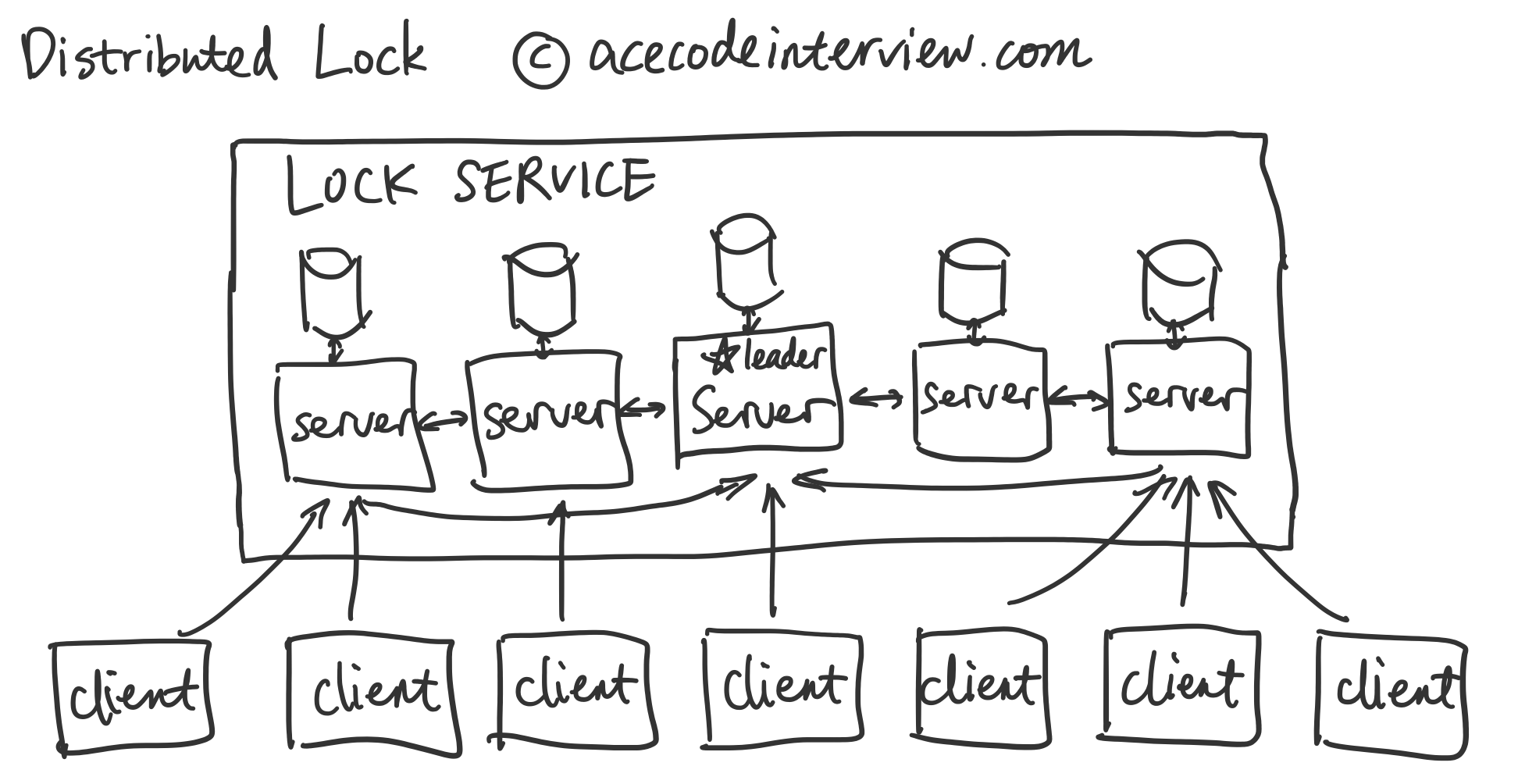
2.2 正确优先
3. 协议设计
我们先从分布式客户端角度考虑问题,此时我们假设我们拥有一个完美的锁,即正确又高效(当然这并不存在),在这种情况下,我们该如何设计客户端与分布式锁之间的沟通方法。
3.1 正常情况
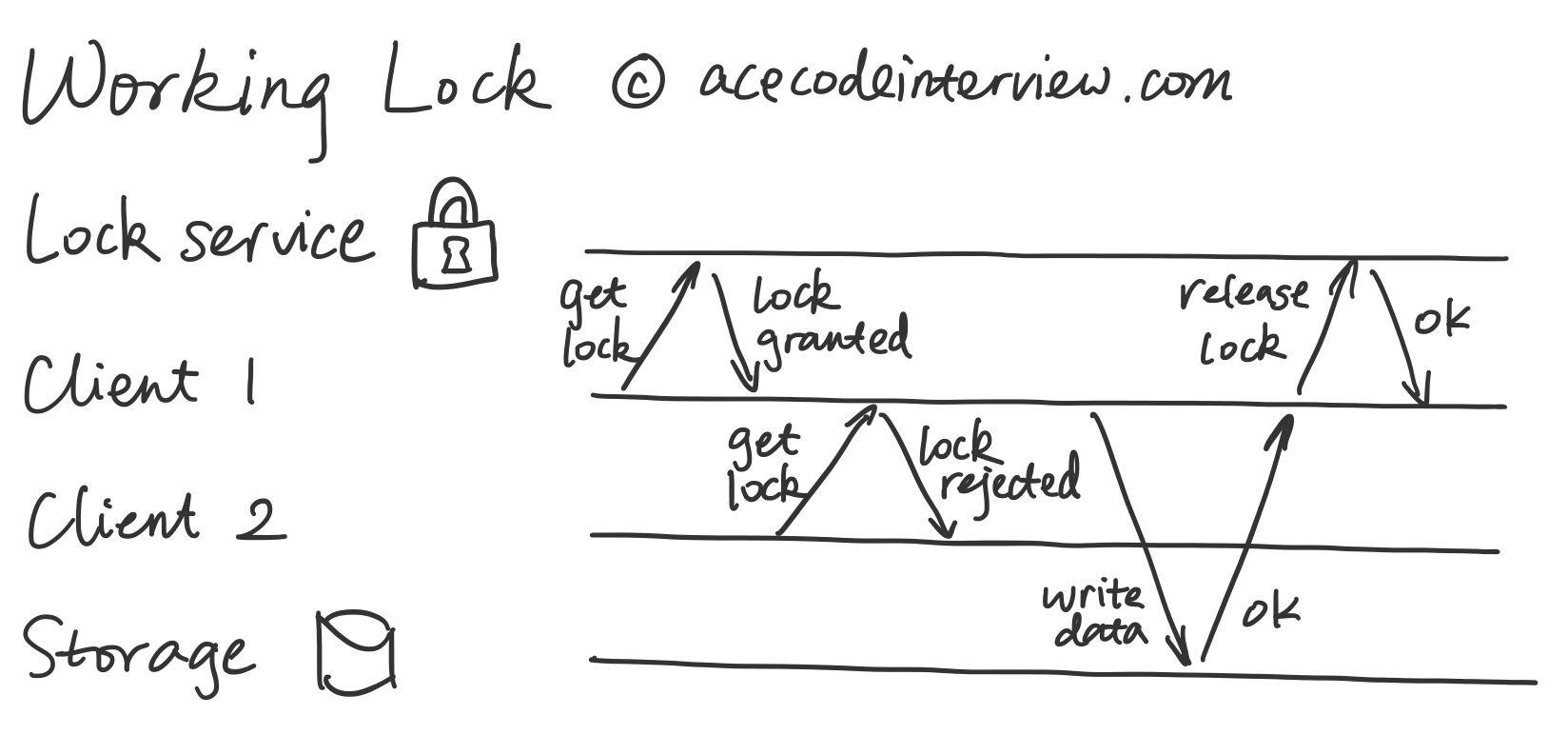
上图描述了每个客户端都正常工作的情况。客户端只需要采用跟多线程锁 (Multi-thread Lock) 一样的策略,先试图获取锁,如果成功,就开始进行运算,修改资源,最后释放锁;反之,就等待锁的释放。
3.2 客户端宕机
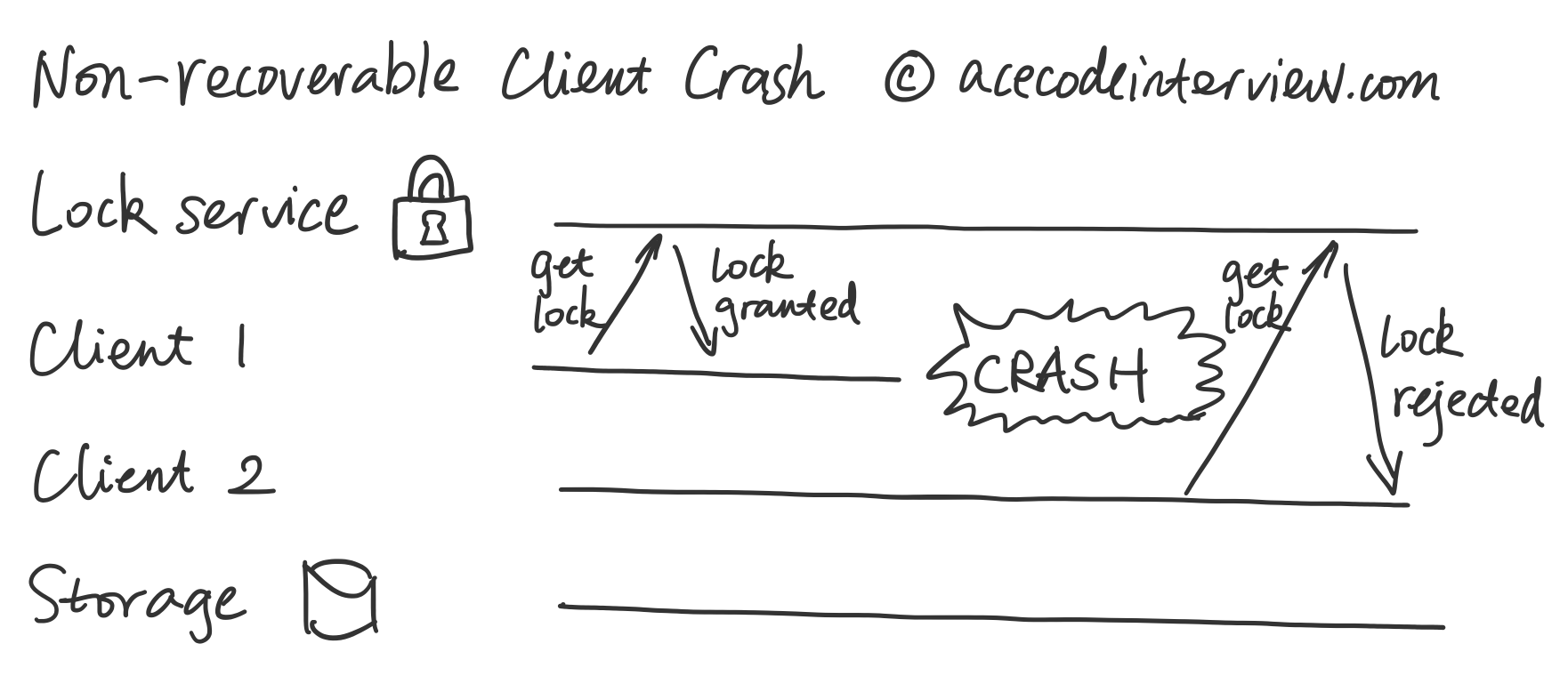
从上图可以看出,一旦客户端 1 宕机,客户端 2 就永远无法拿到锁了,所要进行的运算无法进行,相关的资源无法被修改,造成无法修复的问题。
由于客户端的网络连接可能长期中断,背后的机器可能已经关机,锁服务不能依赖于客户端的稳定性,甚至不能假设客户端过一段时间会恢复。此时我们就要做好最坏的打算,认为客户端已经永远下线。
此时我们就需要在锁服务中设计超时 (Timeout) 的恢复机制,即在一个事先约定好的时间窗口过后,锁会自动释放。
到这里,我们已经可以满足一个多数时候正确的锁的要求了。如果面试官的要求是效率优先,那么我们可以就此打住。
3.3 Fencing(正确优先)
上一节提到的超时恢复机制会造成一个新的问题。当我们追求绝对正确的锁时就需要解决这个问题。
从上图中可以客户端 1 在锁失效后,可能因为自身的进程被系统暂时中止等原因而继续认为自己拥有锁。此时它就会继续进行计算以及对资源进行修改,其结果就是客户端 1 和客户端 2 反复做了运算并且同时改动了资源。
有的同学可能要问,客户端 1 可不可以看一下时钟,算一下自己的锁还有效与否呢?答案是即使看了也不能保证上图情况不发生。这牵涉到分布式系统设计时一个隐含的假设:机器间时钟可能不一致,同时在合理的成本下不存在使它们绝对一致的方法。客户端和锁服务的时钟如果出现了偏差,加上网络传输中的时间消耗,客户端 1 无法精确地知道自己的锁还是否有效。
下面我们来看怎么解决这个超时恢复机制引起的问题。
我们需要引入称为 Fencing 的机制来让锁服务给每个客户端要求的锁返回一个单调递增的 Fencing Token。
从上图可以看到,一旦有客户端拿着旧的 Fencing Token 想要来修改资源时,该修改就会被拒绝,保证资源不被破坏。
4. 分布式系统设计
上一章里讲解了锁服务和一组分布式的客户端如何通讯,所用的假设是存在一个完美的锁服务。本章我们就要来设计锁服务本身,我们由浅入深,正确性要求从低到高来一步一步接近理想中的完美分布式锁服务。
4.1 效率优先
当正确性要求不绝对的时候,我们可以使用一组 Master-slave 系统来构建我们的服务。Master 承担所有读写的要求,Slave 作为纯备份,在 Master 宕机情况下称为新任 Master。
这样的系统旨在做到最终一致性 (Eventual Consistency),即 Master 中的锁相关信息会异步写到一个或者多个 Slave 中。这样做获取锁的效率非常高。
为什么说这样做的正确性不绝对呢?前面提到的最终一致性就意味着,一旦 Master 宕机了,新的 Master 不一定有完整的数据。这些还没来得及同步的信息就丢失了。
有些同学可能会想提出新的方案 - 我们能不能牺牲一点效率来增强正确性,让 Master 完成跟所有的 Slave 的同步工作完成以后再向客户端返回获取锁的信息呢?并不可以,因为根据我们之前提到过,在每个服务器都可能随时宕机的情况下要尽量保证锁服务仍能运行。一旦有一台锁服务中的机器宕机了,任何客户都不能获得锁以及解锁了,在分布式环境下做这个牺牲就有点得不偿失了。
尽管我们不能简单地按照这个方法来做,但是这条思路仍然值得我们挖掘 - 如何同时满足以下两点:
让锁服务的机器都同步状态之后再向客户端返回结果
不要求锁服务中的机器全部在线
沿着这条思路,我们探索实现正确优先的锁实现方法。
4.2 有领导的分布式锁服务 (Distributed Lock with Leader)
在这种设计里,我们把之前的 Master-Slave 模式做一些修改,为表区分,我们暂且称它为 Leader-follower。首先,该系统中的 Leader 如果宕机,需要有一个选举 (Election) 机制,使得每个节点可以有共识 (Consesus),确定下一任的 Leader 是可以被多数节点认可。
在这里我们要简略介绍一下共识机制。我们对这个共识机制的要求是每一次锁服务的决定需要得到大多数 (Majority) 节点的赞同才能继续。我们可以使用这个共识机制选取一个 Leader,此时大多数的节点已经认可了这个 Leader。此后客户端只需要向这个 Leader 发送获取锁的请求。Leader 在使用二阶段提交 (2-phase commit) 的方法得到大多数节点的认可之后,才会向客户端返回获得锁的确认。这样即使在小部分节点宕机的情况下,锁服务依然可以照常运行。在 Leader 节点宕机之后,我们可以使用前面提到的共识机制来选举新的 Leader,并且依靠大多数节点上的状态备份将原本 Leader 的状态恢复。
上面的描述是一个适合在面试中讨论的简化版的叙述,因为我们只需要将领导选举 (Leader Election) 部分省略掉,就能比较全面的表述这个逻辑,而恰恰就是领导选举,是一个复杂的,很难在面试过程中讲清楚的机制。
一个符合以上描述的共识算法是 Zab,为 Zookeeper 所使用。下面是关于 Zookeeper 和 Zab 的一些延伸阅读:分布式系统协调员 ZookeeperZookeeper 是一个高性能分布式系统协调服务 (Coordination Service),它采用类似于文件系统的简洁通用的接口,我们可以利用它轻松实现分布式系统同步一类的操作。还在为协调分布式系统而烦恼?今天就教你怎么做个合格的动物园管理员! 罗辑爱思系统设计
罗辑爱思系统设计
另一个符合要求的算法是 multi-paxos,Paxos 算法的变种,在下一节里会提到。
4.3 全分布式锁服务
之前提到的方案是有领导的,以下的方案我们来看看怎么在没有领导的全分布式情况下实现锁服务。

我们逻辑上采用一组 Proposer,一组 Acceptor 和一组 Learner 来实现之前 4.1 中提到的两点。每台服务器可以同时承担多种逻辑上的责任,比如既是 Proposer,也是 Acceptor 和 Learner。
Proposer 会接受客户端的信息,询问所有能联系上的 Acceptor 是否已经有其他客户端已经获得了该客户端想要获得的锁,如果没有的,告知 Acceptor 它要进行获得锁的准备工作 (Prepare)。在此询问之中,Proposer 会对这个请求给出一个独特的请求序号,方便 Acceptor 找到唯一一个最大的请求序号。序号的生成可以使用服务器纳秒级别的时间 + 该 Proposer 的序号。
如果 Acceptor 表示同意,它会承诺 (Promise),它不会在接受序号低于 Proposer 所请求的序号的请求。如果 Acceptor 已经承诺将锁给别的客户端,那么 Acceptor 会在承诺中返回已经接受的请求序号以及锁的潜在所有者。
Proposer 会检查是不是大多数 (Majority) 的 Acceptor 都同意给客户端这把锁。如果是的,Proposer 会向所有能联系上的 Acceptor(要达到多数)提出获得锁的请求 (Proposal)。如果不是,提出将锁给锁的潜在所有者。
Acceptor 检查请求序号是不是仍是最新,如果是的,回复同意,并告知 Learner。
Learner 一旦发现多数的 Acceptor 已经达成一致,就广播这个结果。同时客户端可以获得锁。
以上是对共识 (Consensus) 算法 Paxos 的一个概括的表达。如果对 Paxos 算法的细节感兴趣,希望论证其正确性,那么请阅读这篇 Paxos 讲义以及这篇 Paxos 实例讲解。
4.4 Leader or Not
4.2 和 4.3 中的两个方案都要求达到共识 (Consensus),只是 4.2 达到的共识是哪台机器是领导,而 4.3 中的共识是哪台客户端有锁,本质上是很接近的。
从实现锁服务的角度上来说,两者的区别在于,4.2 中有领导的机制可以在完成领导选举之后更高效地进行之后的锁的分发,而不需要像 4.3 中每次都从头开始达到共识。毕竟领导选举只会在领导宕机情况下发生,发生次数会远少于锁的分发,所以相对而言,4.2 中提到的有领导的方案更优。
5. 参考资料
Paul Krzyzanowski. (2018). Understanding Paxos
Mike Burrows. (2006). The Chubby lock service for loosely-coupled distributed systems
Flavio P. Junqueira, Benjamin C. Reed, and Marco Serafini. (2011). Zab: High-performance broadcast for primary-backup systems
Henry Robinson. (2008). A Brief Tour of FLP Impossibility
Michael J. Fischer, Nancy A. Lynch and Micahel S. Patterson. (1985). Impossibility of Distributed Consensus with One Faulty Process
Angus Macdonald. (2018). Paxos By Example
Davide Cerbo. (2019). Everything I know about distributed locks
Owen Jia. (2019). Zookeeper's Election Algorithms and Deep Explanation of Crack Problem
Benjamin Reed, Carlos D. Morales. (2012). Apache ZooKeeper
Frank Kane. (2020). ZooKeeper explained
Scott Leberknight. (2013). Distributed Coordination With ZooKeeper Part 4: Architecture from 30,000 Feet
Marco Serafini, Michael Han. (2017). Zab vs. Paxos - Apache ZooKeeper
java知识分子. (2018). 如果你想搞懂“分布式锁”,必须要看这篇文章 ,看了很意外!
咖啡拿铁. (2018). 再有人问你分布式锁,这篇文章扔给他
shashibhusan, adenprior. Mutex lock for Linux Thread Synchronization
在正确优先的设计中,clients和非常leader的servers之间是什么样的通信?我的理解是create lock是邮leader 发起,得到majority followers agree之后就算是完成了(commit)。如果client通过非leader的servers读lock,有可能不能读到刚刚created的lock - 有的server有可能正好不是majority。这可以保证write consistency but not read consistency. consistency here means linearizability. 不过反正读不到lock也不用影响正确性,因为这个client如果试图去get lock,肯定得和leader联系,leader上肯定有正确的lock info。这个是邮consensus protocol保证的。
•
•
分享 ›



Last updated