Design Monitoring System
实时监控系统是每一个网络服务的刚需,每个后端工程师都多多少少接触和使用过。 这道题主要考察 Streaming Service 的应用,监控系统作为一个 Streaming Service 的经典实例,牵涉到 Streaming Service 上游的 Publisher 和下游的 Consumer 如何合理配置,来实现监控系统所涉及到的种种功能。
实时监控系统是每一个网络服务的刚需,每个后端工程师都多多少少接触和使用过。
这道题主要考察 Streaming Service 的应用,监控系统作为一个 Streaming Service 的经典实例,牵涉到 Streaming Service 上游的 Publisher 和下游的 Consumer 如何合理配置,来实现监控系统所涉及到的种种功能。
本题的一个变种是直接问设计 Streaming Service,这时候就需要更深入地讨论 Streaming Service 本身,涉及更多关于存储,分区,容错等等的话题。另一种变种是设计在线广告计数系统来统计每个广告有多少用户看过。
1. 理解需求
1.1 商业目的
帮助网络服务实时监控服务状态并在出现问题时发出警报。
1.2 功能性需求
监控事件 (Event) 发生的数量,比如 Error Rate, Service Throughput
监控事件 (Event) 发生的时长,比如 API 的返回时间
支持查询 Event 在时间上的分布
支持查询时长类 Event 在一定时间范围内的平均时间,P90, P95
预设警报阈值并在偏离阈值时触发警报
Wildcard 查询事件并归总监控
1.3 非功能性需求
时效性 (Time-sensitive) - 监控数据允许分钟级延迟,警报及时触发
扩展性 (Scalability) - 支持监控来自亿级用户网络服务产生的海量事件
可用性 (Availability) - 监控系统本身具有高可用性
灵活性 (Flexibility) - 支持用户自定义的事件
可靠性 (Reliability) - 输出相对正确的监控数据(允许一定范围的误差)
1.4 不需要支持的功能
日志监控 (Log Monitoring)
Stack Trace Monitoring
2. 资源估算
2.1 假设
同时监控 10k 种事件
每种事件平均每秒触发 1000 次
2.2 估算
QPS - 1000 * 10,000 = 10M
存储
高保真秒级原始数据 - 10M * 20B (每个事件存储大小) * 24 * 3600 * 7 (保存7天) = 200 MB * 600k = 120TB
经过压缩后的分钟级数据 - 10M / 60 * 20B * 24 * 3600 * 60 (保存60天) = 16TB
经过压缩后的小时级数据 - 10M / 3600 * 20B * 24 * 3600 * 5 * 365 (保存5年) = 8TB
3. High-level Diagram
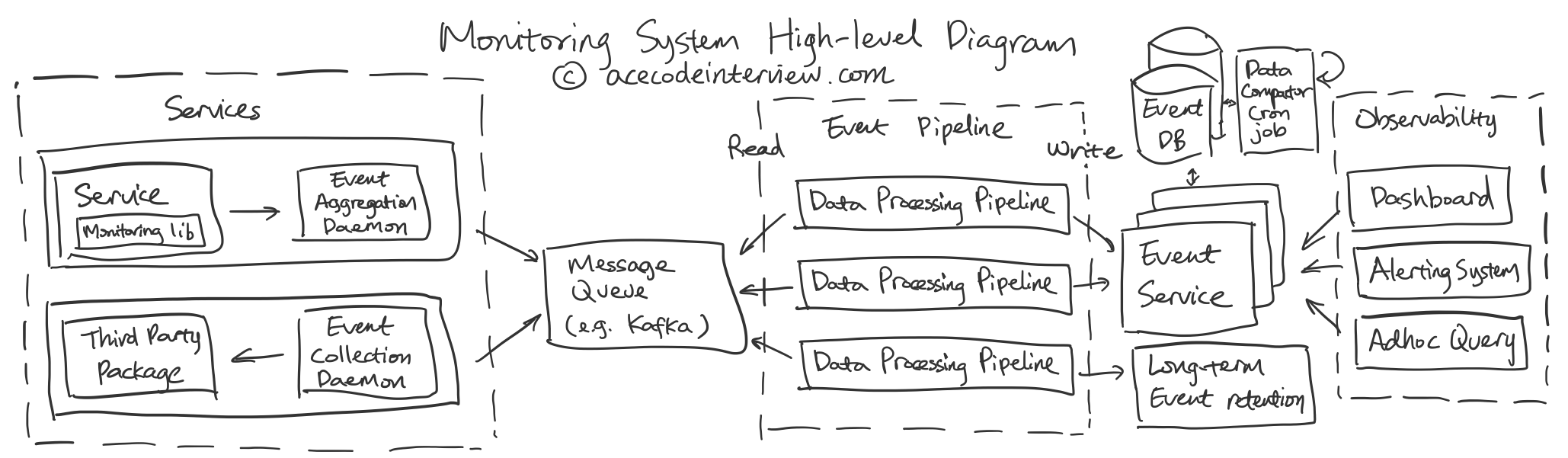
4. 核心子服务设计
4.1 事件采集
事件数据可以有两种来源:
从自有服务的服务器端使用的 Monitoring Library 采集并发送的本地的数据整合 Daemon。
对于非自有服务如 Apache Server,我们可以认为它是一个黑箱。这样我们需要一个数据采集 Daemon 来主动完成采集操作。
事件采集可以使用以下的格式:
Event Name 用来唯一表示一个事件,比如以毫秒计的某服务的某 API Call 的端到端延迟。
Value 包含所要监控的数据。
比如计数类,可以是 count = 1 或者 100
比如长度类,可以是 latency_in_ms = 100
Event Name 和 Event Type 会有一一对应的关系,传输一次之后,后续服务就可以记录下来,避免每次都传输。类似的,另一种方式是要求每个新的事件名称需要跟系统事先注册它的信息,在这里就是 Event Type。这样我们可以完全避免在每个单一事件收集时加入不必要的信息。
Event Type 在这里可以有计数类和长度类。这个 Event Type 可以帮助指导后续的数据处理步骤,对于这个数据的读取模式是什么样的。比如计数类,往往是读取一定时间范围内的数量,而长度类,往往是读取平均长度,P90 长度等等。
事件的时间戳可以以毫秒级的精度收集,然后传递到后续的数据处理步骤。
4.2 事件数据整合和传递
当事件数据从源头收集完毕之后,该数据会经过一系列的传递步骤。使用一个 Message Queue 可以大大简化这个过程。所有的上游服务器会将采集好的或是经过一定整合处理的数据集中发送到 Message Queue。 Message Queue 此时存储有来自所有上游服务器的数据并允许一系列下游的事件数据处理进程来对事件数据进行读取。这些数据处理进程相互独立,比如一个处理分钟级别的平均值,一个处理小时级别的 P90。这些进程完成处理后会把数据发送到 Event Service 做存储。
在此过程中,事件数据会被整合压缩。我们下面就来讨论该如何决定具体在哪几个环节发生整合。
决定取舍的因素:
事件来源服务器负载及带宽
事件数据精度(是否允许近似)
读取灵活性
存储空间
读取速度
下面我们就来对比三种方案,下面以计数类作为例子。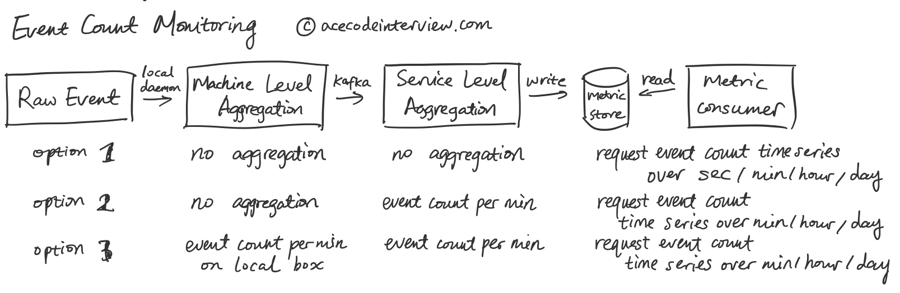
从方案一到方案三,数据的整合压缩越来越靠前,缺点是使得上游的服务器使用更多资源处理数据,一定程度上降低事件数据的精度,降低读取的灵活性,优点是减少上游服务器耗费的带宽以及需要存储的数据,提高读取速度。我们可以根据实际需求来进行取舍。
比如,get_user_request.hit 每秒可能发生上百上千次,原始时间戳是以毫秒计的,考虑到后续访问不需要这么高的精度,我们可以考虑在上游将时间戳降低到秒级或者分钟级,并将次数累加。
长度类的事件的 P50/P90 访问情况下,数据整合后的精度损失更加明显,使用 Histogram 可以一定程度上压缩数据,但不能保证在更大时间范围内进一步计算的时候数据的绝对准确性。这时候如果我们的要求是数据的绝对准确,那么我们就只能保留原始数据。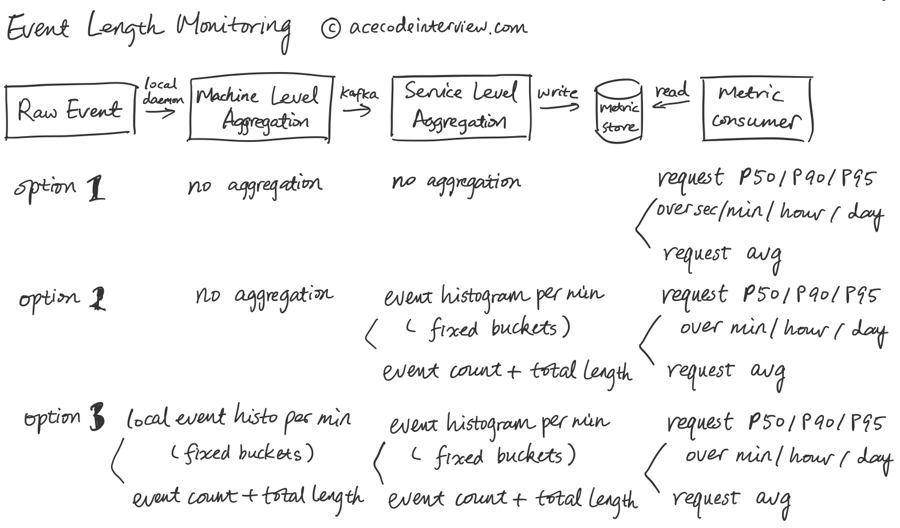
当然,我们可以同时传递存储原始数据和整合过的数据来满足不同的数据使用需求。
4.3 事件读取
事件服务 (Event Service) 一方面接收并存储从 Message Queue 送来的数据,另一方面接受读取请求并进行最终的事件数据处理。
事件服务需要支持丰富的访问方法,读取可能会使用以下步骤:
Wildcard 匹配一个或者多个事件名
读取一定颗粒度(比如秒级)的数值平均,加总或其他整合方式
读取一段时间(比如一周)内的 Time Series
4.4 事件数据库
事件服务最初接收到的事件数据最初是以秒级或分钟级的精度,随着时间的推移,旧的数据不再需要这么高的精度,慢慢可以从秒级或分钟级到小时级到天级。一个定时开启的数据处理任务会对旧的数据进行压缩为新的数据腾出位置。旧的数据会以更低的精度存在于数据库中继续允许读取。同时我们仍可以在文件系统保留一份原有精度的数据,以方便之后有潜在的恢复精度的需要。
4.5 警报系统
警报系统会以很高的频率不断读取监控目标的最新数值并且和预设的阈值进行比对,一旦超过规定的范围,警报系统就可以将相关信息发送给工程师来做应对。
5. 数据结构与存储
5.1 Event Cache & DB
6. 接口设计
6.1 Monitoring Library
6.1.1 事件采集
我们先考虑事件的记录者要怎么简单地使用监控系统记录事件,下面提供一种思路。
表示对于数值类的 event_key 做 +value 的操作。
监控一段代码从头到尾的运行时间。
6.2.2 发送事件
事件通过标准的 Kafka 格式发送
6.2 Event Service API
由于这个服务只会跟内部系统交互,而服务需要能于其他服务高效合作,这里我们倾向于选用 RPC over REST。
6.2.1 写入事件
6.2.2 读取事件
7. 扩展性,容错性,延迟要求
7.1 扩展性
只需要在每台需要监控的服务器上部署轻量级的后台程序
系统使用分布式的 Message Queue 来传递事件
各类事件处理进程可以相互独立地对事件数据进行处理
事件服务是 Stateless 的,支持横向扩展
事件数据库定期进行数据压缩,保证数据量随时间增长较慢
事件数据库支持分布式
7.2 容错性
事件采集阶段可以通过本地日志的方式存储未整合的事件数据来避免服务器宕机的数据丢失
事件数据传递阶段同样可以通过文件系统或数据库的方式在 Message Queue 中存储所有等待传递甚至是已经完成传输的数据,以此来避免 Message Queue 本身宕机
事件整合处理进程会以不同速度读取 Message Queue,Message Queue 对于每一个 Consumer 可以存储 Checkpoint 来记录读取到的位置,以此来避免事件处理进程宕机
7.3 延迟要求
端到端分钟级的延迟要求帮我们排除了 MapReduce 之类的设计
如果需要保证更低的延迟要求,我们可以减短上游的 aggregation window,使得数据更快速地到下游
8. 监控和警报
监控系统需要一套额外的监控系统来监控其本身。这套系统规模更小,但需要使用尽可能独立于系统本身的部件来搭建。
9. 扩展话题
之前我们讨论了计数类和长度类的数据传递,其中涉及到的数据整合方式包括 Sum, Average, P90, P95。
下面我们考虑一种新的数据整合方式,Unique Count,以及如何在数据流中实现这种整合方式。想象我们要统计网站有多少个独立访客。这时候我们就需要对用户进行去重。最简单的做法是对每一个独立访客的 ID 进行 Hashmap 存储并且计算 Unique Count。这样的做法需要大量的内存。如果可以允许近似,那么 Hyperloglog 就是一个很适合处理去重的算法,有兴趣的同学可以了解一下。
10. 参考资料
Colin M. (2017). Storing JSON in database vs. having a new column for each key
Vishnu Gajendran. (2018). Building a reliable and scalable metrics aggregation and monitoring system
Salman Ahmed, Deepak Wadhwani. (2019). Building a reliable and cost effective logging system at Box
Erin Baez. (2020). Statsd Lets You Measure Anything in your System
Ian Nowland. (2019). Datadog: a Real-Time Metrics Database for One Quadrillion Points/Day
Manolis Karpathiotakis, Dino Wernli, Milos Stojanovic. (2019). Scribe: Transporting petabytes per hour via a distributed, buffered queueing system
Last updated