范围索引 - 如营业时间,用户可以搜索餐厅是否现在开门。实现上我们可以利用数据库的两列 A, B 来表达一天内的时间区间,一列 C 表达周几。这样使用数据库的多条记录就可以对以周为单位的开关们情况进行建模,在这个基础上辅助上节假日的特别开门时间就更完善了。可以用 (C, A asc, B desc) 来编制索引,来优化检索速度。
关键词索引 - 如店名,菜名,可以将这些信息做类似传统搜索引擎的逆向排序。传统索引和逆向排序的细节实现在 Google 搜索引擎系统设计题解一文里有具体讲解,供大家做印证。
位置信息和餐厅类型的匹配相对简单固定,我们着重讨论关键词搜索。下面我们考虑关键词 “cheap chicken wings in downtown”。Query Understanding. Heath V. (2015). Reading Between the Lines: How We Make Sense of Users' Searches
可以看到,其中 “Cheap” 对应一个类型标签 (“$”),“Chicken Wing” 可以对应菜名或者店名,”downtown” 对应位置或者店名。要准确理解用户的搜索意图,我们需要将其中每个部分拆开并找到可能的对应。Query Processing. Heath V. (2015). Reading Between the Lines: How We Make Sense of Users' Searches
在对搜索关键词进行语义分析后,搜索流程如下:
根据用户输入的城市,地区或是地图范围找到相关的一个或者多个分片 (Shard)。
在每个分片中:
找到所有范围内 Business ID。
根据搜索关键词中提到的类型,店名,菜名,位置等进行筛选
根据勾选的类型标签进行筛选
将各分片中的 Business ID 汇总
将 Business ID 排序 - 根据一定的规则或者模型按照以下几点因素计算一个分数,并以此为依据排序:
和用户之间的距离 (Distance)
商户的质量 (Quality) - 比如餐厅的评分
用户搜索的匹配程度 (Relevance) - 搜索时 Relevance Score 可以与 Business ID 一起返回。
产品层逻辑根据 Business ID 找到商户具体信息返回给移动端
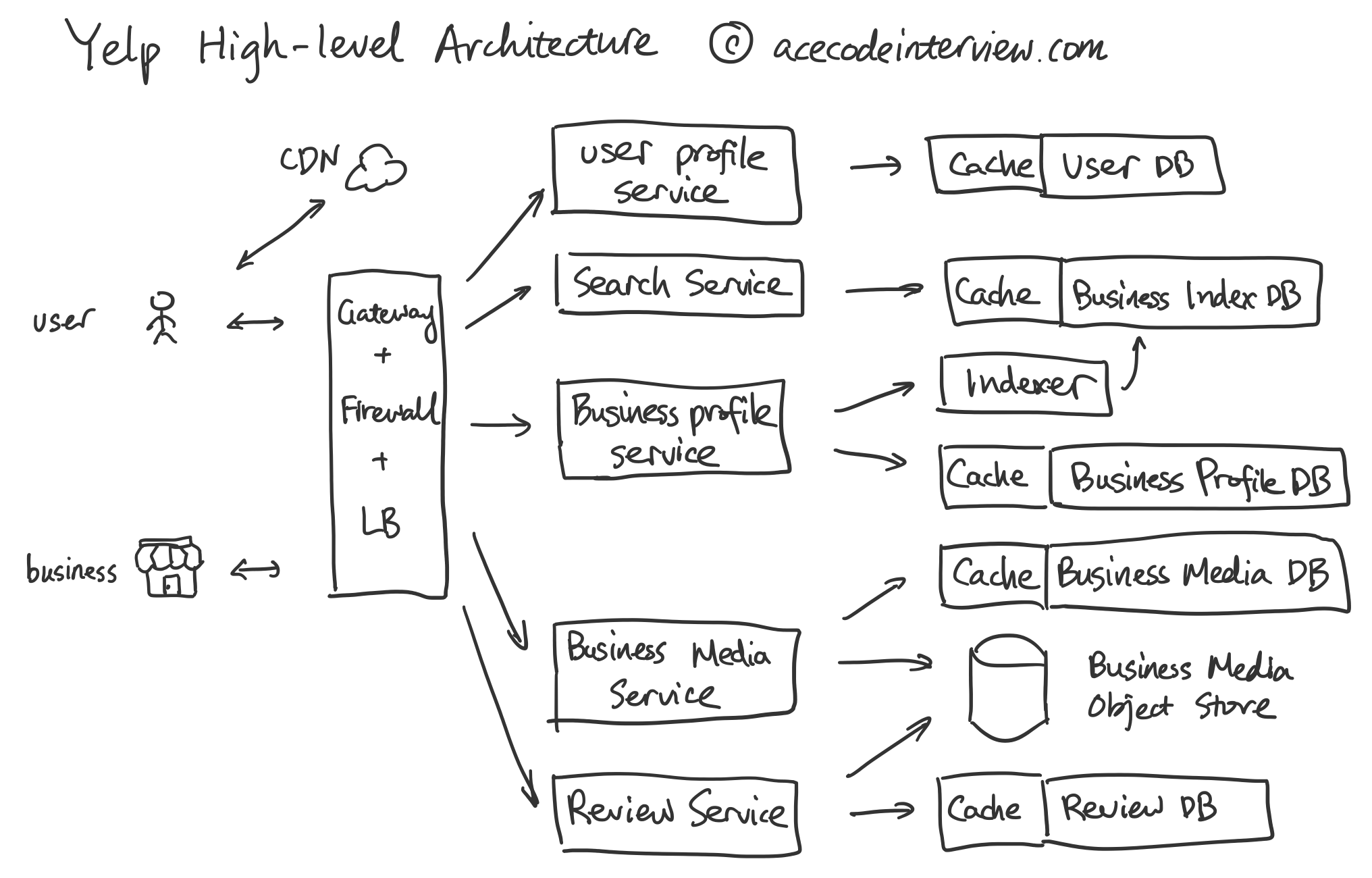
4.2 评价打分服务
用户在找到想去的餐厅之后,往往会参考餐厅的评论和打分,来决定是否会去以及点什么菜品。
评论打分系统是一个 Read-heavy 的服务,因为读评论打分的人数远大于写评论打分的。在设计数据库的时候,我们就要考虑把评论数据库和打分数据库按照餐厅来分区 (Shard),而不是按照用户。我们进一步考虑,往往相邻的地区的数据会容易出现同一次访问中,所以分区方案可以跟搜索一样,使用 Google S2 根据区域来划分。
用户可以上传餐厅的图片或者视频到餐厅的主页或是其中一条评论中,这些图片和视频的完整数据会存在 Object Store (e.g. S3),而 S3 链接会存入 Business Media DB,如果该图片或视频是属于某一条评论的,那么可以额外加一列给出评论 ID。这样可以方便我们在检索餐厅所有图片和视频的时候找到那些属于评论的图片或视频。
本地热门的多媒体可以通过部署到就近的 CDN 来提高访问速度。
当用户查询多媒体服务希望获取餐厅的所有照片和视频的时候,
5. 数据结构与存储
5.1 Business Profile DB
Cache & DB
Business ID | Business name | S2 Cell ID (Sharding Key) | Address | Menu Link | Website Link | Description
5.2 Business Media DB
Media ID | Business ID (Sharding Key) | Media URL | Review ID (Index)
5.3 Review DB
Cache & DB
Review ID | Business ID (Sharding Key) | Content | Author ID
HTTP GET api/v1/search?query=cheap%20chicken%20wings%20in%20downtown&map_area=San%20Francisco&filter=open_now
Response - List of Rendered Businesses
HTTP POST api/v1/business/{business_id}/reviews
HTTP POST api/v1/business/{business_id}/ratings
HTTP GET api/v1/business/{business_id}/reviews?last_review_id=123&page_size=5 (同时返回一组评论和打分信息并提供 Pagniation 支持)
HTTP GET api/v1/business/{business_id}/reviews/{review_id} (同时返回该评论的内容和打分信息)
HTTP GET api/v1/business/{business_id}/average_rating (返回平均分)
 Hilbert Curve - s2geometry.io. S2 Cells
Hilbert Curve - s2geometry.io. S2 Cells
 Yelp Filters
Yelp Filters

 Query Understanding. Heath V. (2015). Reading Between the Lines: How We Make Sense of Users' Searches
Query Understanding. Heath V. (2015). Reading Between the Lines: How We Make Sense of Users' Searches Query Processing. Heath V. (2015). Reading Between the Lines: How We Make Sense of Users' Searches
Query Processing. Heath V. (2015). Reading Between the Lines: How We Make Sense of Users' Searches