为了让 Autocomplete 服务在用户使用时达到极低的延迟,我们需要对流行指数数据库中存储的信息做预处理。考虑到用户请求本质上是根据前缀补全并排序,我们引入处理前缀查询专用的数据结构 Trie。Walid Wahed, Tiffany Han, Jay Shenk. (2018). How We Built Prefixy: A Scalable Prefix Search Service for Powering Autocomplete
假设前缀长度是 L, 该前缀下的所有节点数量是 N,需要返回的结果数量是 K, 以上算法的时间复杂度是 O(L + N + K + (N-K)logK)。其中 K + (N-K)logK 指的是维护一个大小为 K 的最小堆来存储流行指数最大的 K 个节点。实际情况下,由于 K 是一个较小的常数,复杂度可以简化为 O(L+N)。
我们可以通过进一步的预处理将时间复杂度降低到 O(L),即提前最每个节点下的前十最流行的关键词直接存在节点里,如上图所示。通过增加预处理的计算量,使得读取时间更快。在 Autocomplete 的应用场景下,由于我们可以限制 Trie 中的最大深度来给 L 一个限制,O(L) 相当于 O(1),已经很理想了。
4.3.3 方案三
基于 Trie 的预处理的思路,我们可以更直接地使用 Hash Table 来存储所有前缀与前十流行的关键词的对应关系,复杂度同是 O(1),但读取速度会更快。这样做的好处是不需要处理树状结构,可以很容易地存入 Redis 之类的 KV Store;缺点是数据形式不如树状结构紧凑,会耗费更多储存空间来存储前缀。在分布式系统中,我会优先考虑读取速度而牺牲存储。在之后的设计中,我们会基于方案三做设计。Walid Wahed, Tiffany Han, Jay Shenk. (2018). How We Built Prefixy: A Scalable Prefix Search Service for Powering Autocomplete






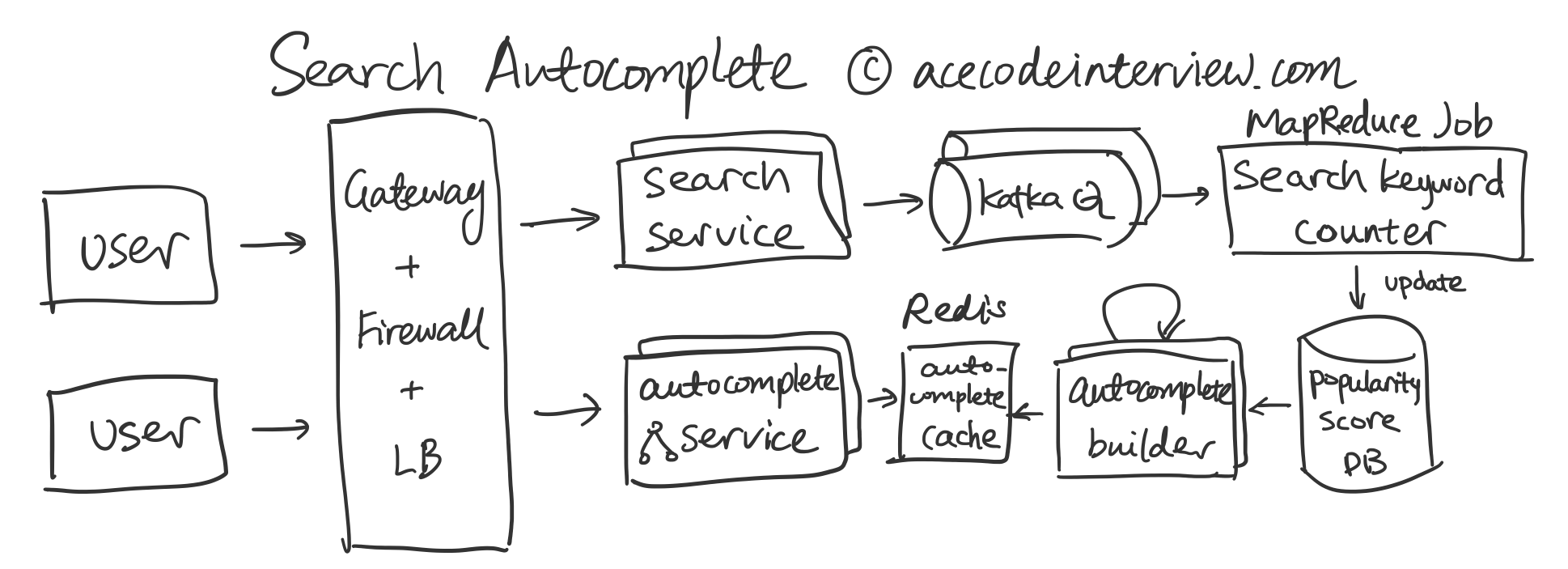
 罗辑爱思系统设计
罗辑爱思系统设计
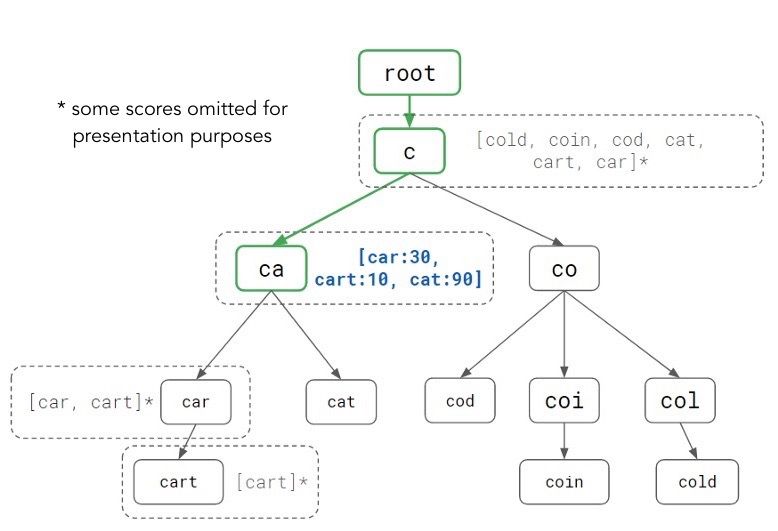
 Walid Wahed, Tiffany Han, Jay Shenk. (2018). How We Built Prefixy: A Scalable Prefix Search Service for Powering Autocomplete
Walid Wahed, Tiffany Han, Jay Shenk. (2018). How We Built Prefixy: A Scalable Prefix Search Service for Powering Autocomplete