Design Web Crawler
爬虫是 Google 搜索的核心组件之一,自从互联网诞生初期就帮助我们整理互联网上的资源,解决了信息发现的难题。今天我们来看看如何设计一款高效的网络爬虫。
这个题目有一些不同的问法,比如爬取 Wikipedia 或是设计 GoogleBot。
1. 理解需求
1.1 商业目的
检索互联网上的公开信息,让用户可以通过搜索引擎方便快速及时地找到有用的信息。
1.2 功能性需求
使用爬虫爬取网站信息 (Crawl)
1.3 非功能性需求
时效性 (Time-sensitive) - 对重要网站更新在短时间内捕捉
扩展性 (Scalability) - 支持全互联网的爬取
有礼貌 (Politeness) - 爬虫需要遵守约定俗成的爬虫规则。不过载服务器;不保持过多的连接;避免管理员禁止的区域等等
高效性 (Efficiency) - 爬虫需要高效地爬取网站,尽量减少反复爬取相同内容
鲁棒性 (Robustness) - 爬虫不会掉入爬虫陷阱,避免死循环和无限空间 (infinite space)
1.4 不需要支持的功能
编制搜引 (Indexing)
通过关键词搜索 (Searching)
搜索结果排序 (PageRank)
2. 资源估算
2.1 假设
500M websites on the internet
average 100 page per website
100KB per page (HTML, JS)
平均2周重新爬取全网一次
2.2 估算
存储 - 500M * 100 * 100KB = 5 PB
QPS - 500M * 100 / (14 * 24 * 3600) = 41335 QPS
3. High-level Diagram
Web Crawler High-level Diagram by acecodeinterview.com
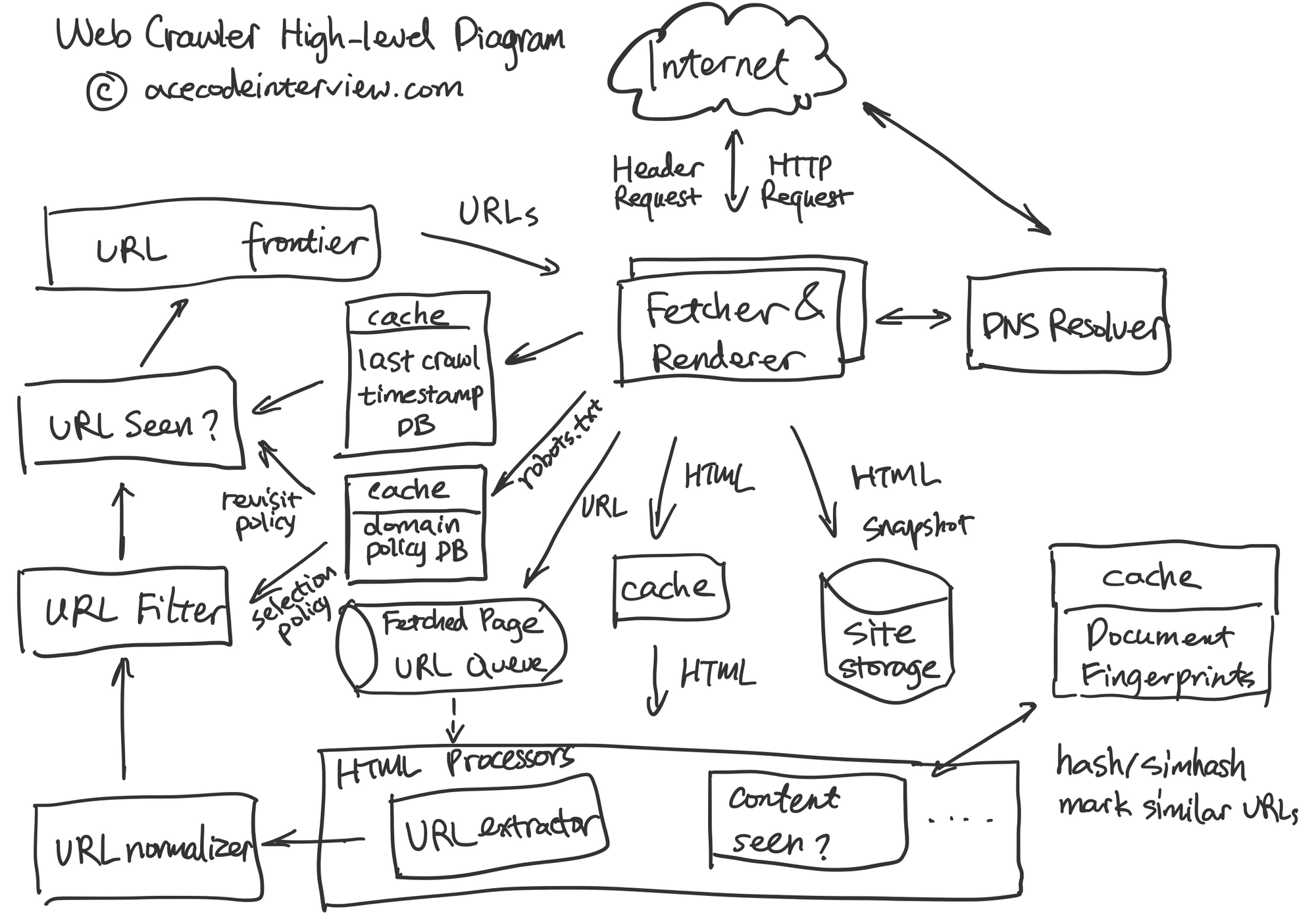
4. 核心子服务设计
爬虫拥有多个核心子系统,下面会一一介绍。
4.1 URL Frontier
Crawling the Web Lecture Slides
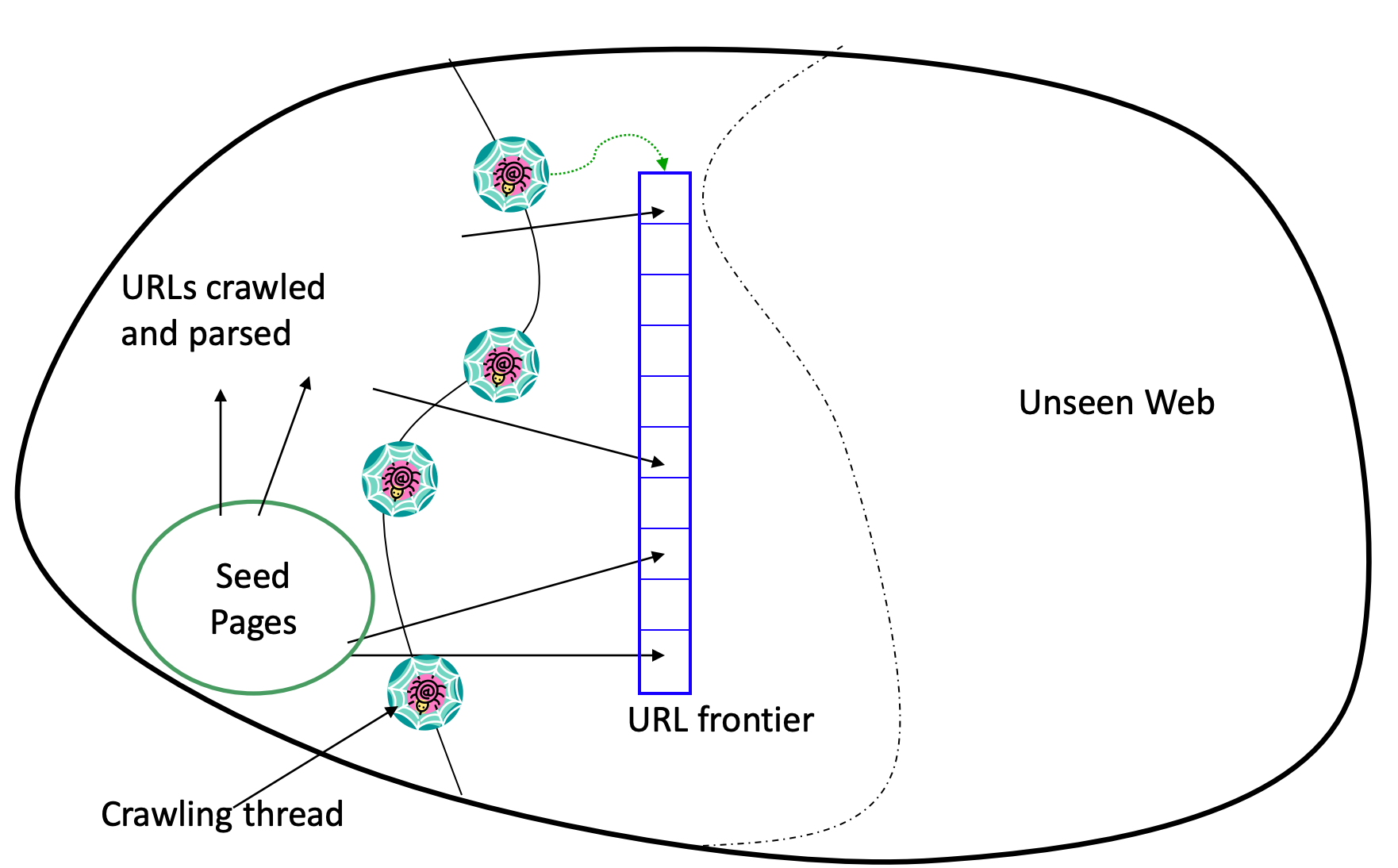
URL Frontier 接收符合要求的链接,并根据链接的优先级以及网站的 Politeness Policy 按一定顺序讲链接发送给 Fetcher 进行爬取。
4.1.1 链接预处理 (URL Pre-processing)
在进入 URL Frontier 之前,链接已经经过了一下几个步骤:
规范化 (Normalization)
相对链接转化为绝对链接
大小写
添加 HTTP 协议
末尾添加 "/"
剔除不符合要求的链接 (Filtering)
robots.txt 中声明排除
多媒体相关链接 (e.g. *.mp3)
会导致爬虫进入爬虫陷阱的链接
检查是否近期爬取过该链接 (URL Seen?)
最近爬取该链接以及高相似度内容链接的时间以及域名重复爬取策略 (Re-visit Policy),决定是否需要爬取。如果不需要,就可以暂时放弃爬取该链接。
4.1.2 链接优先级实现
经过预处理步骤之后,我们已经确认希望爬取这个链接。
下图包含优先级以及 Politeness Policy 的实现细节。此处的设计参考了著名的信息检索经典教材 Introduction to Information Retrieval 的相关章节。URL Frontier Design by acecodeinterview.com
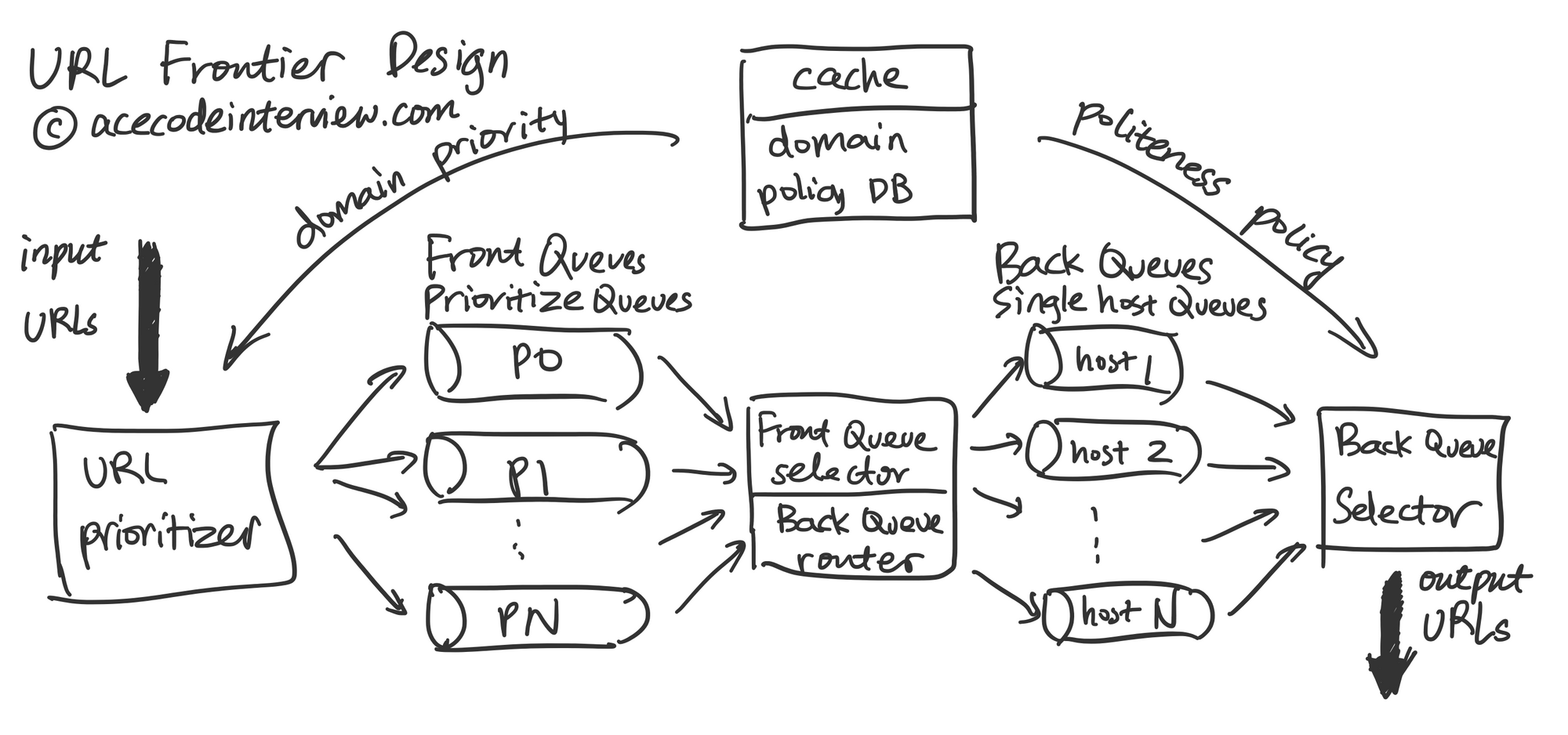
我们首先根据过去爬取网站的经验,网站的访问量以及搜索用户对网站的点击对网站的爬取的优先级做出判断。注意这个过程是在线下完成的,当 URL Prioritizer 需要决定将连接放在哪个优先级的队列时这个过程早已完成,它只需访问 Domain Policy DB 来获得这个信息。
此后,URL Prioritizer 将网站放入一组优先级不同的队列中。Front Queue Selector 同时也是 Back Queue Router,它带有一定的随机性地优先从高优先级的队列中取出连接放入一组 Back Queue,这样既可以保证优先级,也保证低优先级的队列不会被 Starve.
4.1.3 单一域名爬取间隔实现
首先我们考虑一下为什么需要一组 Back Queue。在爬虫的访问模式中,我们往往会在短时间里爬取一个网站的全部内容,如果没有这组 Back Queue,我们很容易导致网站过载。下面是具体实现。
Back Queue 每个队列都只存储单一域名,目的是将控制访问单一域名的间隔时间并且防止过多数量的 Fetcher 同时连接到单一域名的服务器上。Back Queue Selector 可以采取几种策略从这组队列中取出链接。
轮流 (Round-Robin) - 每个队列都有公平的机会被选中,这个简单策略的缺点是,每个域名并没有同样的资源,这样做会使得小网站更容易被爬虫过载,并且在支持 robots.txt 里指定的时间间隔时会需要反复查看所有的队列,造成资源浪费。
使用最小堆 (min-heap) - 用一个最小堆记录每一个队列的最早再次访问时间戳 (Timestamp),每一次爬取完毕后,根据该网站的时间间隔要求将 ts + time_gap 放入堆中。每一次选择下一个爬取链接时,从堆中取出最早在时间戳对应的队列号码,从中找到下一个链接。这样做可以在较低的时间复杂度 (LogN) 的情况下找到下一个链接,并且保证同时每个域名只有一个连接。如果我们需要支持单一域名多个连接来爬取大型网站,当时间间隔要求被满足时,可以同时释放多个单一域名链接。
Mercator 爬虫的设计者推荐配置 Fetcher 线程数量三倍的 Back Queue。这样可以保证 Fetcher 足够忙碌。
4.2 Fetcher & Renderer
4.2.1 爬取流程
Fetcher 承担了爬虫系统主要跟外界互联网沟通的责任,消耗大量的带宽,获得大量的数据。
使用定制的异步 DNS 解析器 (DNS Resolver) 在单机上同时解析多个域名,此过程中缓存解析完成的 IP 地址,以备之后使用。
检查域名的 Robots.txt 文件是不是短期内更新过,如果没有,更新该文件,将其内容存入相关数据库,并判断当前链接是否仍然符合爬取条件。
使用独特的 user-agent 发送 HEAD Request,根据 last-modified 的值来决定是不是继续爬取。
使用独特的 user-agent 发送 GET Request,有需要的时候配合 Renderer 获取完整 HTML。
将爬取时间和 HTML 存入相关数据库,缓存和文件系统。
将链接放入 Task Queue 异步等待进一步处理,比如链接抓取,HTML 相似内容分析,HTML 结构数据抓取,甚至是构建知识图谱。这里的异步可以支持服务的扩展性 (Extensibility)。
4.2.2 爬取 Javascript Sites
由于近些年 Javascript Framework 的崛起,大量网站使用像 React, Angular, Vue.js 这类的工具进行搭建。传统的 HTML 爬虫只能看到网站的骨架,没法爬到有意义的内容。于是我们就需要引入 Renderer 来运行这些 JS 代码,生成完整的 HTML 并且基于它去做进一步的处理。
这种做法称为服务器端渲染 (Server-side Rendering),可以使用的工具有 Gatsby 以及 Next.js。
4.2.3 规模化 (Scale)
因为 Fetcher & Renderer 占用大量资源,是爬虫速度的主要瓶颈,需要认真考虑它的规模化,即如何实现大量 Fetcher 和 Back Queue Selector 沟通并获得适合的链接来高效爬取。
简单做法 - 我们可以简单地将使用一系列没有区别的 Async Worker 从 Back Queue Selector 中按需要获取链接进行爬取。这样我们不需要考虑在 Worker 之间如何平均分配工作。缺点是链接无法优化地分配到合适的 Worker。
按地域分配 - 一个直接的优化是根据地域来分配 Worker 资源,比如北美,欧洲和中国的网站可以使用专属的 Worker 集群来爬取,加快访问速度。
按域名分配 - 一个更复杂的优化。每个域名被分配到专属的 Worker,每个 Worker 会同时处理多个域名。这样使得 Worker 可以借助本地优势 (Locality),在内存中存储跟管辖域名相关的信息而不需要反复访问其他服务,比如存储域名爬取策略。同时,这个做法会导致 Worker 工作量不平均,此时可以使用 Consistent Hashing 的方法来合理分配 Worker 资源,实时加减机器来满足要求。
4.3 相似内容分析 (Content Seen?)
相似内容分析可以帮助爬虫理解相同或者不同网站上的核心内容是不是类似。注意这里我们所说的相似内容通常并不是整个网页的 HTML 完全一模一样,而是核心内容的相似。
Hash - 使用 Hash 算法判断网站是不是完全相同,正如上述的原因,这不足以判断多数的类似情况。
近似算法 - 我们先将 HTML 中的核心内容提取出来,然后使用近似算法对其生成一个签名,相似内容的签名应该可以通过算法判断相似性。备选的算法包括 Jaccard index, cosine similarity, minhash, simhash, fuzzysearch, latent semantic indexing, standard boolean model。
当相似度达到一定的阈值,我们就可以认为它们拥有同样的内容,此时爬取其中一个链接就相当于爬取了全部链接,我们可以减少其他链接的爬取频率。这样可以有效地节省爬虫资源。
我还想举一个实际的例子来说明这个组件的重要性,一个网站可能提供多语言支持,每个链接都可以拥有后缀 ?lang=en/fr/zh/...。其中可能只有中文和英语是有不同内容的。爬虫在一次爬取完各种语言版本的网站之后就可以通过相似内容分析找到相似内容的链接,减少爬取频率。我们可以进一步想象如果每个链接有三五个这样的后缀可以排列组合会怎么样。
5. 数据结构与存储
5.1 Domain Metadata Cache & DB
DOMAIN ID
DOMAIN NAME
LAST CRAWLED TS
CONCURRENT CONNECTION LIMIT
TIME GAP BETWEEN CRAWLS
5.2 URL Metadata Cache & DB
URL ID
URL
LAST CRAWLED TS
EXCLUDED FROM CRAWLER
SIMILAR CONTENT GROUP ID
5.3 HTML Store
HTML 本身使用 BigTable 存储(文件系统由 Google File System 实现)。 采用域名倒序来构建 Key,将 HTML 以及 Indexing 完毕后的数据都可以存入 Big Table。BigTable Design from BigTable Paper
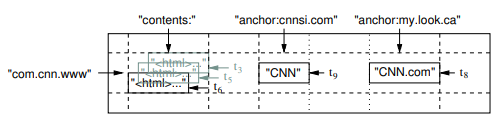
GFS 更多信息请参考以下链接:
6. 接口设计
网站的管理员通过 robots.txt 来跟爬虫进行单向沟通。robots.txt 有一套成熟的规范。同学们可以以维基百科的 robots.txt 为例来学习一下这套规则。
7. 扩展性
URL Frontier 采用了两组可扩展队列
Fetcher & Renderer 可以扩展 Worker 数量
HTML 存入 BigTable 支持横向扩展
其他服务大多不存储状态,支持横向扩展
Cache & DB 可扩展
8. 监控和警报
Queue Health
Async worker load
爬虫陷阱检测
缓存命中率
数据库使用比例
文件系统使用比例
9. 参考资料
Christopher D. Manning, Prabhakar Raghavan & Hinrich Schütze. (2008). Introduction to Information Retrieval Book
Christopher D. Manning, Prabhakar Raghavan & Hinrich Schütze. (2008). The URL Frontier
Allan Heydon & Marc Najork. (1999). Mercator: A Scalable, Extensible Web Crawler
Tech Dummies. (2019). Web Crawler System Design Video
Paul Han & Jae-Hoon Sul. (2002). Polite Crawler
Wikipedia. Web crawler
Google.com. Google Crawl and Index Help Center
Scrapy.org. Scrapy Architecture overview
Patrick Hathaway. How to Crawl JavaScript Websites
当crawler从url queue (back queue)取走一个待爬的url,这个URL是马上从queue去除(de-queue)吗?如何知道一个URL被成功爬取了?如果要求exactly once crawl呢?
•
•
分享 ›
这个问题牵涉到 Crawler 的 Error handling - 合理的解决方法可以是 1)URL 在被 Crawler 取走之后直接 Deque 2)如果 Crawler 在爬取过程中发生 Exception 时将 URL 重新放回 Front Queue(如果该 URL 的 Back Queue 还存在也可以考虑放 Back Queue) 这个做法并不严格保证 Exactly once crawler,因为还有别的 Failure Scenario,比如 Back Queue 如果挂了怎么恢复等等。Exactly Once 是一个相对复杂的问题,可以参考 Kafka 的 Exactly Once Delivery 的做法 - https://www.confluent.io/bl... 或者直接用 Kafka 做这个 Queue。 对于这个使用场景来说,我会 argue Exactly Once 的要求没有必要,at least once 或者 at most once 会更合适,毕竟反复爬取是不会对爬取的最终结果有影响的。
•
•
分享 ›


Last updated